关于回归分析中的置信区间和预测区间
不少初学者往往混淆均值的置信区间和个体的预测区间(prediction interval),在有的统计软件中,同时给出回归线的置信区间和预测区间,致使有的初学者搞不懂它们有什么区别。
其实二者很容易区分,置信区间是针对因变量均值的区间,而预测区间是针对因变量个体值的区间。不难理解,针对均值的置信区间肯定要窄一些,而具体想预测某一个体值,那区间肯定要宽,因为误差会很大。
比如,让你预测一个高中班级中学生的平均身高,跟让你预测该班级中具体某一个学生的身高,你觉得哪个误差更大呢?对于一个班级的均值,即使你什么信息都不知道,估计预测的也差不到哪儿去,而让你预测班中的张三同学的身高,那你可能就不知所措了。
(1)均值的置信区间
线性回归中,我们假定,对于每一特定的x值,其对应的y值应该是来自一个服从某一均值和标准差的分布。例如,调查温度与手足口发病率的关系,温度=10℃,假定其对应的手足口发病率是来自一个服从均值为10(1/10万),标准差为4(1/10万)的总体分布。
当我们调查这一数据时,得到的是这一总体分布中的某一随机数值(所以说y是随机变量)。根据样本数据建立的回归方程,可以估计出当x等于某一数值时,y的估计值(也就是y的总体均值的估计值)。比如根据方程式:
发病率=-0.011+0.995*温度
可以估计出,温度=10℃时,对应的手足口发病率的均值估计为9.94(1/10万)。
由于是总体均值的估计,那就必然会有估计的误差(标准误),这一标准误是可以计算出来的(公式略,格式不好调整,感兴趣的等本书出版后看书)。
因此根据标准误、均值估计值,便可以估计置信区间。这一置信区间反映的是样本估计yi的均值的这一范围有多大的信心包含了总体均值。
如月份温度=10℃时,手足口发病率均值的95%置信区间为(6.64,16.25)。这说明,对于温度=10℃这样的月份,我们有95%的信心认为,(6.64,16.25)这一区间包含了手足口发病率的总体均值。其暗含的意思就是(尽管不是很严谨),有95%的信心认为,对于温度=10℃的所有月份,它们对应的手足口发病率的均值在(6.64,16.25)之间。这句话虽然不是很严谨,但其隐含的意思其实就是如此。
(2)个体的预测区间
如果我们已知某一特定的x值,想根据该值预测对应的具体y值,也就是预测某个具体值,这就是对个体的预测。例如,调查了多个地区1-12月的气温和手足口发病率,已知11月的温度=10℃,据此预测某一地区11月手足口发病率是多少。这跟均值的置信区间不同,它不是预测所有地区的11月份的平均发病率,而是预测这一个地区11月的发病率。因此其标准误必然更大,当然也可以计算出来(公式略,格式不好调整,感兴趣的等本书出版后看书)。
由于标准误大了,该区间必然要比均值的置信区间要宽。例如,已知某地11月的温度=10℃,如果要预测这一地区11月份的发病率,其95%置信区间为(-1.55,21.44)。可以发现这一区间远远比均值的置信区间要宽得多。
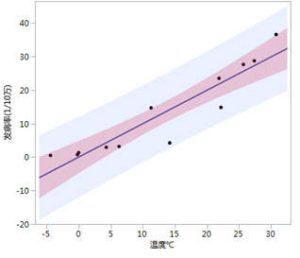
下图给出了置信区间预测区间,可以看出置信区间(红色区域)较窄,而预测区间(蓝色区域)要宽得多。
![]()